try openclaw
然后就是最近比较火的openclaw,当然也要尝试一手。
install
首先安装必要的依赖:npm install -g node-addon-api node-gyp
安装openclaw的方法有三种,首先是arch用户可以通过yay -S openclaw-git通过AUR下载,但是AUR带有git后缀的一般是源码编译,一般来说会比较慢。
不过openclaw本质上是nodejs应用,所以其实应该只是npm安装。
第二种就是直接通过npm/pnpm安装,npm install -g openclaw@latest需要调整nodejs版本为22.16+.
第三种是,ollama现在官方支持使用openclaw,只要ollama launch openclaw就可以完成安装和使用。
考虑到openclaw本身也需要烧token,还是选择使用ollama local model + openclaw.
其实都需要nodejs 22.16+,可以参考上一期中的nvm管理nodejs版本的部分来进行nodejs版本切换。
总之,可以在用nvm调换nodejs版本到22.16+之后,通过npm install -g openclaw@latest完成openclaw下载。
configure openclaw
如果有ollama,可以先ollama launch openclaw并且选择自己已有的本地模型,无论是否成功实现ollama和openclaw的连接,都可以构建一个local model和openclaw的config文件。
之后再运行openclaw onboard打开openclaw.
第一次打开会有提示选择onboarding mode,选择manual可以获得更大的自由度。
我因为运行过ollama launch openclaw并且选择了本地的qwen3.5模型所以会有一个提示:
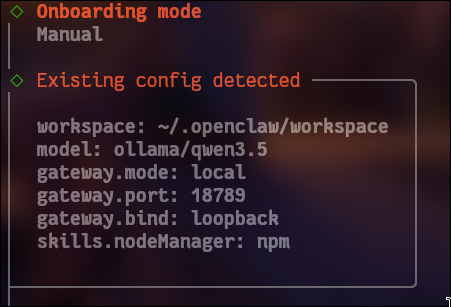
但是还是选择reset(full reset, config + creds + sessions + workspace).
由于我们使用的是本地ollama模型来接入openclaw,所以在what do you want to set up?界面选择local gateway(this machine);在之后的model/auth provider中选择ollama作为provider:
在ollama的配置中,选择local,因为openclaw只要能听懂我说的话+会发指令即可(别太笨就行,至少我现在这么认为)
如果直接继续的话系统会自动下载glm-4.7-flash,而且不能自由选择模型。但是这是一个30B-A3B MoE模型,体积不小,如果你的电脑可以运行这个模型也可以直接下一步。我的电脑跑不起来,所以还是换成我已经下好用过的qwen3.5.
关闭openclaw,然后检查.openclaw下的配置文件后发现,文件里没有glm之类,说明下载glm模型应该是openclaw内部的编码,所以输入:
1 | grep -r "glm-4.7-flash" $(npm root -g)/openclaw/ --include="*.js" -l |
找到所有文件中的glm-4.7-flash:
1 |
|
之后批量替换这些文件:
1 | grep -r "glm" ~/.nvm/versions/node/v22.16.0/lib/node_modules/openclaw/ --include="*.js" -l | xargs sed -i 's/glm-4\.7-flash/qwen3.5:latest/g' |
然后重新运行openclaw onboard,走过以上流程,就可以选择模型了:
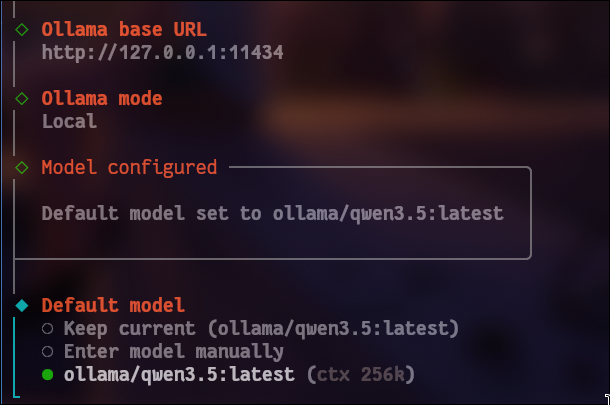
gateway port按照默认18789,gateway bind选择回环(127.0.0.1);之后会选择gateway auth,由于我们是本地模型,所以选择password.
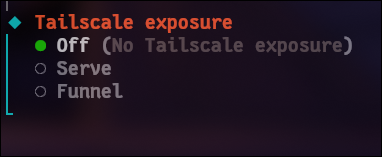
本地不需要tailscale,所以tailscale选择off.
tailscale是一个VPN工具,可以让设备在不同网络下像局域网一样互相访问。
off: 只有本机可以访问openclaw;
serve: 通过tailscale让手机和其他设备也能访问这台电脑上的openclaw;
funnel: 暴露到公网,不安全,任何人都可以访问。
关于密码,本地直接选择enter password now.
set telegram bot
下一步是选择chat channel,我个人比较喜欢telegram和google chat,这里展示telegram.
首先是创建一个bot.
我们打开telegram,找到@BotFather,对他发送一个/newbot创建新的bot.
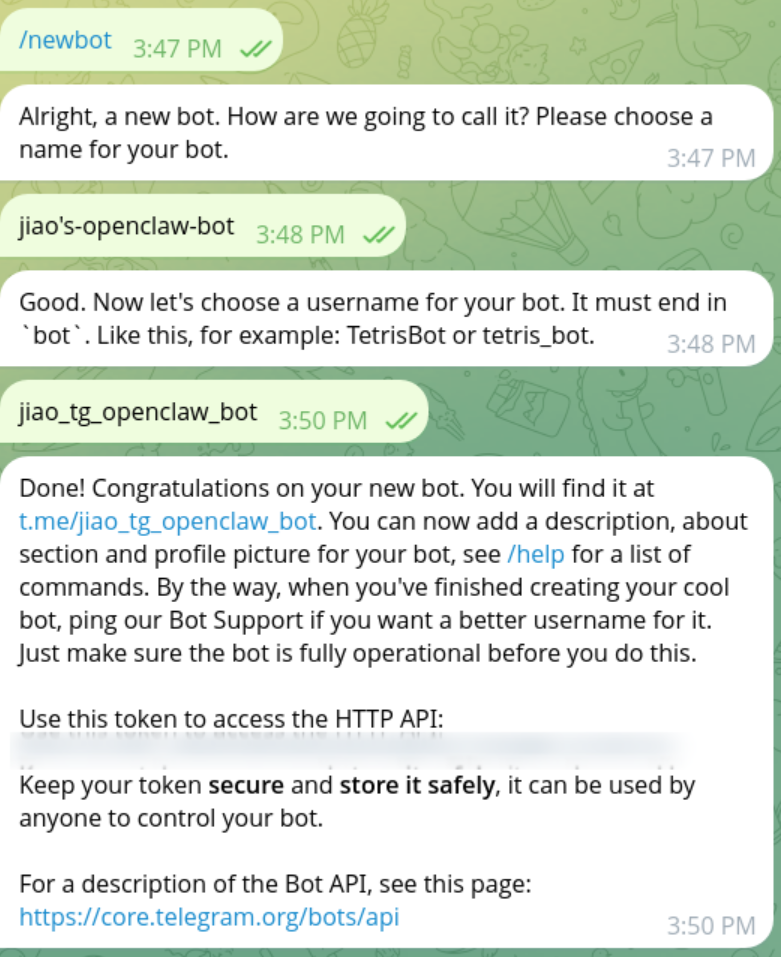
然后记住这个token,把token喂给openclaw就完成了。
如果想要修改bot,可以发送/mybots进行对应修改。
continue openclaw onboard
设置好bot之后就可以选择finish,进入下一步。
之后是选择DM access policies,也就是谁可以使用。
pair就是默认只有被授权用户使用,其他的还有allowlist白名单,允许特定用户使用;public所有人都可以给bot发消息。这里选择pair就好。
下一步是选择search provider,这个用国外的需要API key + visa,但是我的visa卡是0额度的先充钱再花钱,所以就不选了,暂时跳过,不必要。
之后是skill配置界面:
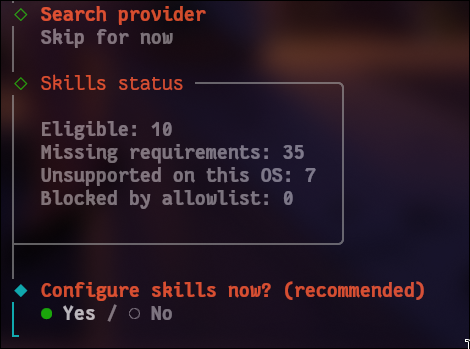
这里看一眼还有什么功能是可用的。
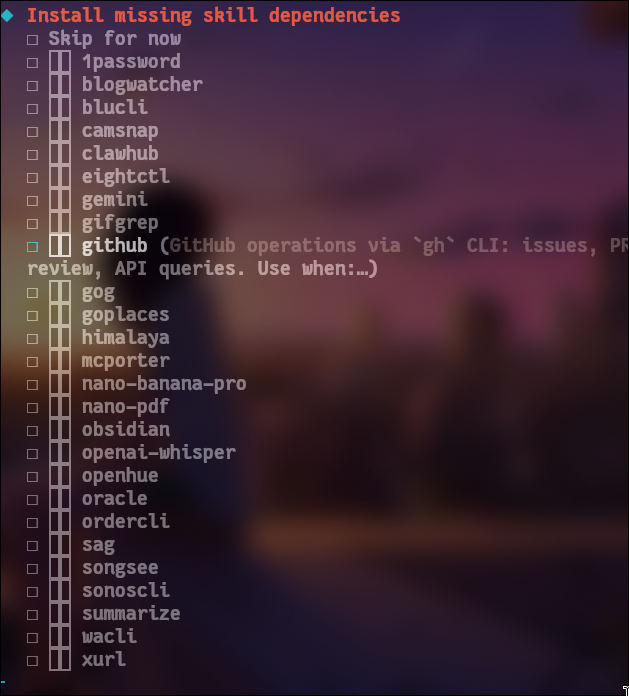
很多我也不认识,问下AI:
效率工具
1password — 密码管理器集成,让 AI 帮你管理密码
summarize — 自动总结文章/文档内容
开发相关
github — 通过 gh CLI 操作 GitHub,管理 issues、PR、代码审查
oracle — Oracle 数据库操作
mcporter — MCP 服务器管理工具
内容创作
blogwatcher — 监控博客/RSS 更新
nano-banana-pro — 高级文本编辑
nano-pdf — PDF 处理和阅读
bsidian — 连接 Obsidian 笔记库
媒体处理
camsnap — 摄像头拍照
gifgrep — GIF 搜索和处理
openai-whisper — 语音转文字(OpenAI Whisper)
songsee / sonoscli — 音乐播放控制(Sonos)
openhue — 飞利浦 Hue 智能灯控制
数据/搜索
gemini — Google Gemini AI 集成
goplaces — 地点搜索
xurl — URL 处理和网页抓取
系统工具
blucli — 蓝牙设备管理
clawhub — openclaw 生态工具
eightctl — 系统控制
himalaya — 邮件客户端
ordercli — 订单管理
sag — 系统管理
wacli — WhatsApp CLI
gog — 游戏平台(GOG)集成
选择自己需要的就好。
还有一些hooks提供额外功能:

同样选自己需要的即可,我选择了后两个,记录我输入的command和开新对话和reset时的上下文。
之后会自动安装gateway service;安装完毕之后会选择启动方式,TUI就是terminal直接用,Web UI就是浏览器打开,这里选择TUI.
set systemd
设置openclaw为后台systemd自动运行,
1 | systemctl --user enable --now openclaw-gateway |
systemctl我相信大家都挺熟的(应该)
主要就几个关键词,
enable: 开启启动(不会立刻启动)enable --now: 开机启动且立刻启动status: 查服务状态stop: 关闭服务start: 启动服务restart: 重启服务disable: 取消开机自启--user/sudo: 不同的服务开启模式,用户只有登录才会运行,root会开机就跑。
1 |
|
test
problem1: pnpm污染
输入systemctl --user status openclaw-gateway,发现没有正常运行,阅读日志后发现有两个错误(其实是一个错误),一个是路径错误,服务指向了pnpm,但是我用的是npm;另一个是node版本,服务用的是v22.12.0,我的是v22.16.0.
我是铸币,之前pnpm下过一次给忘了
关掉服务之后,打开.config/systemd/user/openclaw-gateway.service,把
1 | ExecStart=~/.nvm/versions/node/v22.12.0/bin/node ~/.local/share/pnpm/global/5/.pnpm/openclaw@2026.2.22-2_@napi-rs+canvas@0.1.94_@types+express@5.0.6_hono@4.12.2_node-llama-cpp@3.15.1/node_modules/openclaw/dist/index.js gateway --port 18789 |
改成:
1 | ExecStart=/home/jiao/.nvm/versions/node/v22.16.0/bin/node /home/jiao/.nvm/versions/node/v22.16.0/lib/node_modules/openclaw/dist/index.js gateway --port 18789 |
之后重启服务:
1 | systemctl --user daemon-reload |
problem2: proxy
仍然有一个问题,无法连接到ollama serve,但是ollama serve是在运行的,在.zshrc中有配置:
1 |
|
浏览器输入:localhost:11434,可以查到,curl -v http://localhost:11434失败,同时发现是proxy的问题,那么就在.zshrc中添加本地端口不走代理:
1 | export no_proxy="localhost,127.0.0.1,::1" |
之后刷新终端再次尝试:curl -v http://localhost:11434成功出现ollama is running.
说明本地连接成功。
real test
终端输入openclaw dashboard打开控制台界面(或者是openclaw dashboard --no-open),我这里给出dashboard URL端口是18789,在firefox打开如下:
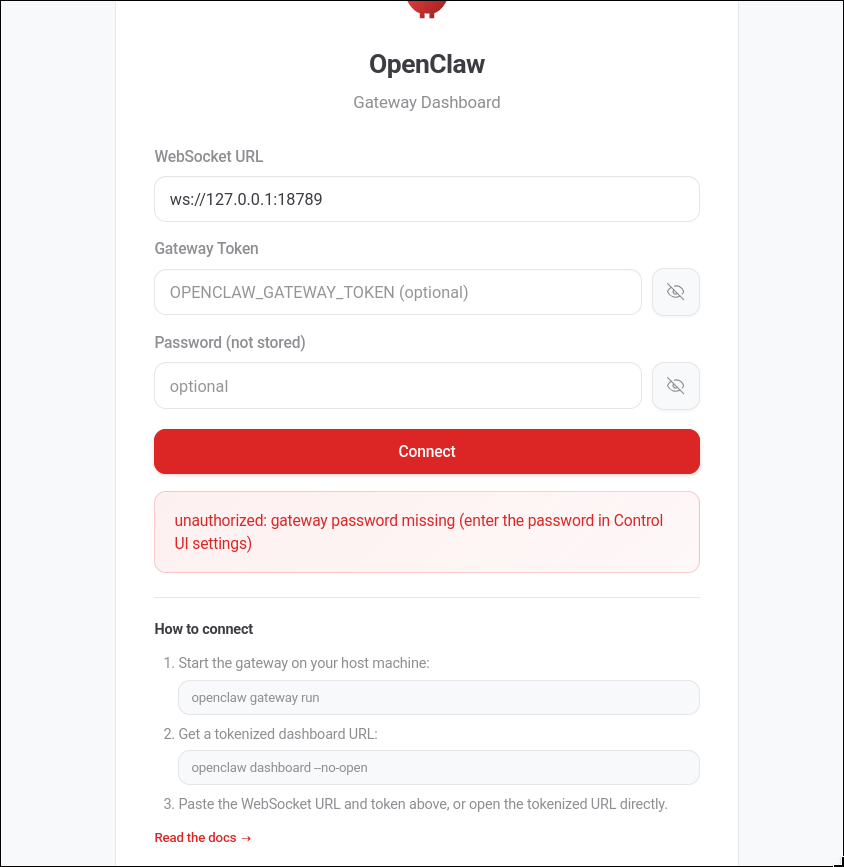
输入密码进入dashboard界面。
如果是要终端交互,输入openclaw tui.
我这里打开终端交互,openclaw tui:
然后我们尝试tgbot.
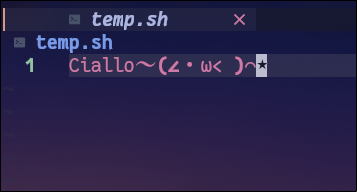
我现在在~/temp.sh中写入:Ciallo~(∠・ω< )⌒★
然后对bot说:请阅读我~/temp.sh中的内容并发送给我
bot的回复是:
OpenClaw: access not configured.
Your Telegram user id: xxxxxx
Pairing code: yyyyyy
Ask the bot owner to approve with:
openclaw pairing approve telegram zzzzzzz
我们在终端输入:openclaw pairing approve telegram zzzzzz
重新发送:
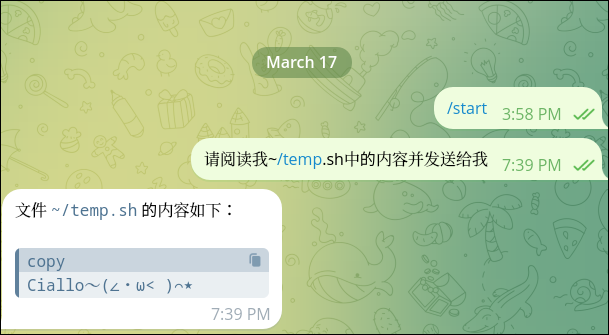
这样我们就实现了一个不用花钱接入外部ai模型API的本地模型驱动的openclaw,再配合我们上一期的try codex,就可以实现我们手机上发一句指令,自己的电脑远程执行指令(编写代码)了。
一些常用命令
| command | description |
|---|---|
| openclaw dashboard | web ui |
| openclaw tui | terminal ui |
| openclaw health | 检查gateway |
| openclaw doctor | 自动健康检查 |
| openclaw logs | 查看实时日志 |
| openclaw models | 查看/切换模型 |
| openclaw sessions | 查看历史对话 |
| openclaw memory | 管理AI记忆文件 |
| openclaw setup | 初始化本地配置 |
| openclaw reset | 重置本地状态 |
| openclaw qr | 生成配对二维码 |
我的用法
我不希望每次开机直接启动,所以写一个脚本,每次需要打开openclaw的时候运行脚本打开。
首先关闭自动开启:
1 | systemctl --user disable openclaw-gateway |
确认真的关闭:
1 | # 检查 gateway 进程 |
然后写一个脚本:
1 | export no_proxy="localhost,127.0.0.1,::1" |
其他问题
- openclaw.json的一些参数
这个文件中,apiKey初始化可能是很奇怪的字符串,如果无法识别,就换成"ollama"或者是"";
streaming开启有些时候会有错误,可以换成"off"
- ollama开启跨域
在.zshrc中写:export OLLAMA_ORIGINS="*"
- ollama开启GPU
我好像之前没写过,这里补充一下。
首先,如果想用GPU推理ollama,需要额外安装ollama-cuda:
1 | pkill ollama |
同时由于我电脑是双显卡,所以要用envycontrol切换显卡:
1 | yay -S envycontrol |
然后要记得把cuda库加入.zshrc:
1 | # CUDA 库路径 |
验证:
1 | pkill ollama |
如果看到gpu_count=1就说明成功。
后续
qwen3.5对于16GB电脑真的很卡,我只好nvim .openclaw/openclaw.json,然后:%s/qwen3\.5:latest/qwen2.5:7b/g…
toys and tools homepage
toys and tools homepage is here.



