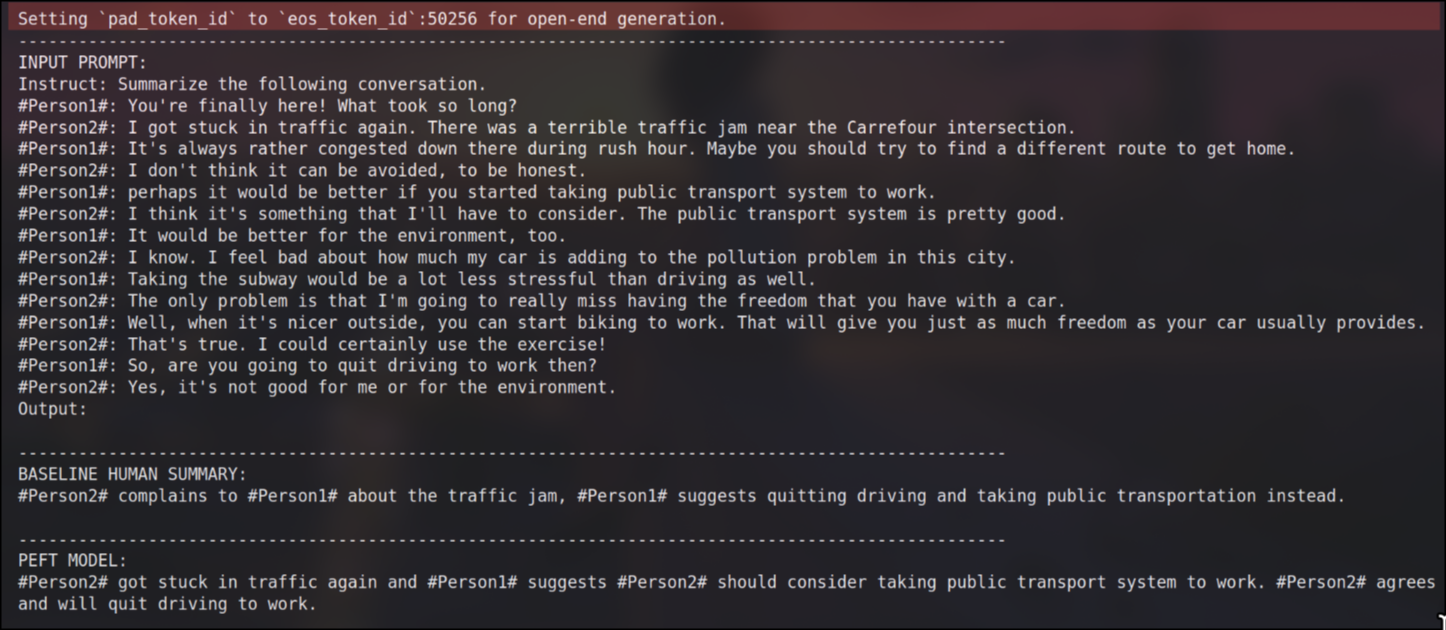
dash_line = '-'.join(''for x inrange(100)) print(dash_line) print(f'INPUT PROMPT:\n{prompt}') print(dash_line) print(f'BASELINE HUMAN SUMMARY:\n{summary}\n') print(dash_line) print(f'PEFT MODEL:\n{prefix}')
diff between evaluate and train:
diffs
train
eval
reason
model
origin_model
ft_model
to show the difference after PEFT
output
output raw text
use partition() to clip output
PEFT model may output extra signal, should be clean
gen()000
pass tokenizer
none
packaged in PEFT
the output here:
evaluate the model Quantitatively with ROUGE metric
ROUGE, is a set of metrics and a software package used for evaluate automatic summarization and machine translation software in natural language processing, in Gisting evaluation.
it will compare the produced/generated summary to a reference one.
it compares summarizations to a baseline summary that usually created by humans.
dialogues = dataset['test'][0:10]['dialogue'] human_baseline_summaries = dataset['test'][0:10]['summary'] # from dataset\['test'\] fetch 10 dialogue and summary, for generate and compare.
# generate summary for each dialogue. for idx, dialogue inenumerate(dialogues): human_baseline_text_output = human_baseline_summaries[idx] # create prompt prompt = f"Instruct: Summarize the following conversation.\n{dialogue}\nOutput:\n" # original model's result original_model_res = gen(original_model,prompt,100, tokenizer,) original_model_text_output = original_model_res[0].split('Output:\n')[1]
# peft_model's result peft_model_res = gen(ft_model,prompt,100, tokenizer,) peft_model_output = peft_model_res[0].split('Output:\n')[1] print(peft_model_output) peft_model_text_output, success, result = peft_model_output.partition('###')
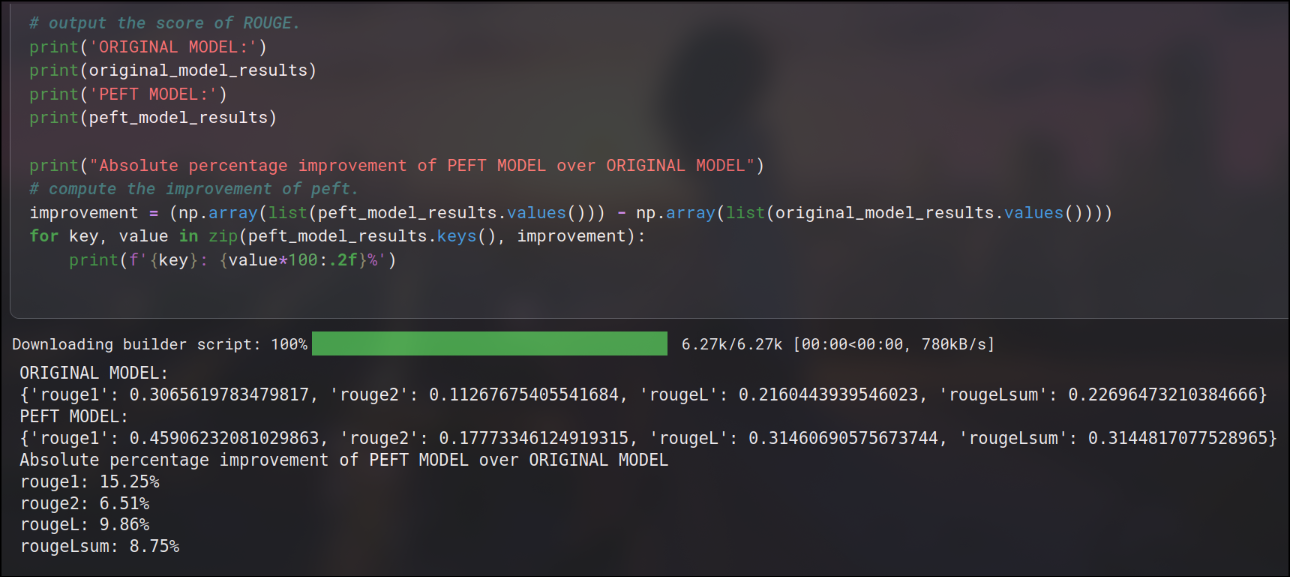
# output the score of ROUGE. print('ORIGINAL MODEL:') print(original_model_results) print('PEFT MODEL:') print(peft_model_results)
print("Absolute percentage improvement of PEFT MODEL over ORIGINAL MODEL") # compute the improvement of peft. improvement = (np.array(list(peft_model_results.values())) - np.array(list(original_model_results.values()))) for key, value inzip(peft_model_results.keys(), improvement): print(f'{key}: {value*100:.2f}%')
so we can find that there is a significant improvement in the PEFT model as compared to the original model model denoted in terms of percentage.